CSS 设计指南 学习笔记 一
Contents
第二章 CSS 工作原理
在本章中作者主要讲解了 CSS 如何对 HTML 添加样式的,并且解释了层叠的工作机制比如当元素的同一个属性被多次设置样式后到底应该选择何种样式,这就要靠 CSS 的层叠机制来决定最终应用哪种样式了。
每个 HTML 元素都有一组样式属性,这些属性涉及元素在文档流中显示时的不同方面,比如在文档流中的位置、边框、背景、颜色等等。CSS 就是一种先选择 HTML 元素,然后设定选中元素 CSS 属性的机制。CSS 选择符和要应用的样式构成一条 CSS 规则。
2.2 上下文选择器
上下文选择器的格式如下:
标签1 标签2 { 声明 }其中标签2就是我们要选择的目标,而且只有在标签1是标签2的祖先元素(不一定是父级元素)的情况下才会被选中。上下文选择器严格来讲应该叫「后代组合式选择器(Descendant Comninator Selector)」。
还有一点要注意的是,上下文选择器以空格作为分隔符,而分组选择器则以逗号作为分隔符,不要弄混。
2.3 特殊的上下文选择器
前面一节作者介绍的上下文选择器是以某个祖先元素作为上下文的,只要目标元素在 DOM 结构「上游」存在这么一个祖先元素即可,无论这个祖先元素和目标元素隔了多少层级都没有关系,但有的时候我们需要比「某个祖先元素」更具体的上下文,这时候我们就可以使用一些特殊的选择器了,比如自选择器 >、 紧邻兄弟选择器 +、一般兄弟选择器 ~ 和通用选择器 *。
2.3.1 子选择器 >
标签1 > 标签2这里的标签2必须是标签1的子元素,也就是说标签1必须是标签2的父元素,而不能是标签2的任何其他祖先元素。
2.3.2 紧邻兄弟选择器 +
标签1 + 标签2在这里标签2必须紧跟在兄弟标签1的后面,否则无效。
2.3.3 一般兄弟选择器 ~
标签1 ~ 标签2在这里标签2必须跟(不一定要紧跟,只需在标签1的后面即可)在其兄弟标签1后面。
2.3.4 通用选择器 *
通用选择器 * 是一个是一个通配符,代表文档流中的任意元素,不过通用选择器 * 通常会搭配一些其他选择器来使用,比如:
section > * {}代表 section 的所有子元素,不过一般情况下很少通过通配符来选择某个元素下的所有子元素,因为这涉及到浏览器性能问题,它会影响网页的渲染时间,我们写的时候是从左到右写的,但是浏览器渲染却是从右到左的,就上面这段代码来说,浏览器会先遍历所有的元素,然后在找出哪些元素的父元素是 section,另外举一个例子,有选择器:
div.container #main > .article {}浏览器在渲染时,先把所有类中包含 article 的元素取出来组成一个集合,然后对每一个集合中的元素进行遍历,如果元素的父元素的 id 不为 main 则把元素从集合中删去。 再然后从这个元素的父元素开始向上找,没有找到一个标签名为 div 并且类名中有 container 的元素,就把元素从集合中删去,直到匹配所有的条件,所以在能不使用通配符的情况就尽量不要使用它。
2.4 ID 和类选择器
作者在这一节介绍了 id 和 class 选择器,为我们选择元素提供了另一种手段,利用它们可以不考虑元素在文档流中的层次结构,只要在元素中添加了 id 和 class 属性和值,我们就可以通过它们的值来找到目标元素。
可以给
id和class属性设定任何值,但不能以数字或者特殊符号开头。
2.4.3 什么时候用 id,什么时候用 class
id 的用途是在页面中唯一地标识元素,所以每个页面中每一个 id 属性值都是独一无二的。而 class 的目的是为了标识一组具有相同特征的元素,也就是说一个页面中可以出现多个相同的类。
对于什么时候用 id 这个问题作者的观点是:
每一个顶级区域都应该添加一个
id,从而得到非常明确的上下文关系,以便编写 CSS 时只选择嵌套在相应区域内的标签。
对于什么时候使用 class,由于 class 的目的是为了标识一组具有相同特征的元素,所以如果当页面中有一组元素具有某种相同的特征,就应该毫不犹豫的时候 class 了。
但是这里也应该注意不要乱用类,避免造成类泛滥,例如:
<nav>
<ul>
<li class="boy"><a href="#">Alan</a></li>
<li class="girl"><a href="#">Andrew</a></li>
<li class="boy"><a href="#">Angela</a></li>
<li class="boy"><a href="#">Angus</a></li>
<li class="girl"><a href="#">Anne</a></li>
<li class="girl"><a href="#">Annette</a></li>
</ul>
</nav>上面这个例子就是一个典型的类泛滥。
2.4.4 id 和 class 的小结
对于什么时候用 id 和什么时候用 class,我想每个人都有不同的看法,这里写说一下笔者的观点,笔者认为能不实用 id 就尽量不使用 id,实际情况是笔者基本不在 CSS 中使用 id,因为在 CSS 的层叠机制中,id 的权重是 class 的10倍,其实很多情况下对某个元素设置某个不一样的样式来覆盖之前的样式并没有效果就是因为之前的样式权重太高,而为了达到效果就要编写权重更高的选择器,所以只有在某个元素需要被 JavaScript 找到的时候才会在某个元素中添加 id ,以便可以通过 document.getElementById() 方法来快速获取需要的元素。
2.5 属性选择器
属性选择器包括属性名选择器和属性值选择器,它们是通过元素的属性和值来获取元素的:
标签名[属性名] 标签名[属性名="属性值"]
例如:
img[title] {border: 2px solid blue;}
a[target="_blank"] {background-image: url(_blank.png);}上面第一段代码意思是,如果某个 img 标签带有 title 这个属性,那么就为它添加一个宽度为 2px 的蓝色实线边框。第二段代码的意思是,如果某个 a 标签带有 target 这个属性,并且这个属性的值为 _blank 那么就为这个元素添加一个背景图。
拓展:
其实除了以上两种属性选择器,还有其他几种属性选择器作者并没有列出来,这里这几种其他的属性选择器作一个简单的介绍:
-
标签名[name^="value"] 让你匹配属性为
name并且属性值以value开始的标签,如:a[href^= "http://"]则匹配所有具有href属性并且属性值以http://开始的标签。 -
标签名[name$="value"] 让你匹配属性为
name并且属性值以value结束的标签,如:a[href$=".com"]则匹配所有具有href属性并且属性值以http://结束的标签。 -
标签名[name*="value"] 让你匹配属性为
name并且属性值包含value的标签,如:a[href*= "renren"]则匹配所有具有href属性并且属性值包含http://的标签。 -
标签名[name|="value"] 让你匹配属性为
name或者以name-开始的标签,如:p[lang|= "en"]则匹配具有lang属性的p标签,不管其属性值是en还是en-us。 -
标签名[name~="value"] 让你匹配属性为
name并且其属性值是具有多个空格分隔的值,其中一个值为value,如有:
就可以用 `p[title~="learn"]` 来选择这个元素。
你应该注意到了这些属性选择器与前面两种属性选择器之间的差别了,通过这些属性选择器我们可以很容易的做出许多意想不到的效果,比如:
```css
a[href$=".pdf"] {background-image: url(pdf.png);}
比如上面这段代码就为链接是 pdf 文档连接的 a 标签添加一个表示这个链接是 pdf 文档的图片,而其他 href 属性的值不是以 .pdf 结尾的 a 标签就不会应用这条样式声明,让用户很清楚的判断这是一个什么类型的链接。
2.6 伪类
伪类这个叫法源自它们与类相似,但实际上并没有类会附加到标记中的标签上,伪类分为两种:
-
UI(User Interface,用户界面)伪类:会在 HTML 元素处于某个状态时(比如鼠标指针位于连接上),为该元素应用 CSS 样式。
-
结构化伪类:会在标记中纯在某种结构上的关系时(比如某个元素是一组元素的第一个或者最有一个元素),为相应的元素应用 CSS 样式。
2.6.1 UI 伪类
-
链接伪类
-
link: 链接就在那儿等着用户点击。
-
visited:用户此前点击过这个链接。
-
hover:鼠标指针正悬停在连接上。
-
active:链接正在i被点击(鼠标在元素上按下,还没有释放)。
注意以上几种链接伪类要按一定的顺序才有效果,为了方便记忆作者是这么建议的:"LoVe?HA!",大写字母就是每个伪类的第一个字母,其实也可以这么记: "LoVe,HAte",其实都差不多就是了。
一个冒号(:)表示伪类,两个冒号(::)表示 CSS3 新增的伪元素。
-
-
:focus 伪类
表单中的文本字段在用户单击它时会获得焦点,例如:
input:focus {border: 1px solid blue;}这段代码的意思就是当用户单击表单中的文本字段的时候,为该
input标签添加宽度为 1px 的蓝色实线边框,需要注意的是,伪类的冒号要紧跟着标签名,之间不能有空格,否则该声明无效。 -
:target 伪类
如果用户点击一个指向页面中其他元素的链接,则哪个元素就是目标(target),可以用
:target伪类选中它,比如:
位于页面其他地方、`id` 为 `more-info` 的那个元素就是目标元素,该元素可能是这样的:
```html
<h2 id="more-info">This is the information you are looking for.</h2>
那么 CSS 规则如下:
#more-info:target {background: #eee;}此时会在用户点击链接转向 id 为 more-info 的元素时,该目标元素的背景就会变成浅灰色。
2.6.2 结构化伪类
-
first-child,last-child和nth-child(n)
e:first-child e:last-child
`first-child` 和 `last-child` 分别代表一组同胞元素中的第一个元素和最后一个元素,而 `nth-child(n)` 则代表一组同胞元素中的任何一个元素,其中 `n` 表示一个整数(也可以是 odd-奇数 或 even-偶数)或者也可以是一个算数表达式(2n + 1),例如:
```html
<ul>
<li>My Fast Pony</li>
<li>Steady Trotter</li>
<li>Slow Ol' Nag</li>
</ul>
ul li:first-child {color: black;}
ul li:nth-child(2) {color: red;}
ul li:last-child {color: blue;}上面的 HTML 应用了上面的 CSS 规则后,无序列表的第一个元素字体颜色就会变成黑色,第二个元素变成红色,最后一个元素就变成蓝色。
2.7 伪元素
顾名思义,伪元素就是文档中若有实无的元素,下面是几个比较常用的伪元素。
-
::first-letter伪元素,比如:p::first-letter {font-size: 300%;}这样
p标签的第一个字母大小就会变成原来的 3 倍了,而其他元素则不会。 -
::first-line伪元素:可以选中文本段落的第一行。 -
::before和::after伪元素
e::before e::after
可用在特定元素前面或后面添加特殊内容,比如:
```html
<p class="age">25</p>
.age::before { content: "Age: ";}
.age::after { content: " years";}这里需要注意的是,对于 ::before 和 ::after 伪元素,其 content 属性是必须的,还有就是搜索引擎不会取得伪元素的信息(因为它在文档流中并不存在),因此不要通过伪元素添加一些对搜索引擎来说是重要的内容。
拓展:
其实伪元素前面冒号可以是两个也可以是一个,但是为了区别伪类,笔者建议大家还是使用两个冒号。还有一个要注意的是,比如通过 ::before 和 ::after 伪元素为 class 为 pseudo-element 添加两个伪元素,则生成的两个伪元素分别处于 pseudo-element 元素的内部,也就是说是 pseudo-element 元素的子元素,并且分别位于 pseudo-element 元素的内容的最前面和最后面,代码如下:
<div class="pseudo-element">
<p>Pseudo Element</p>
</div>
<style>
.pseudo-element::after,
.pseudo-element::before {
content: "";
}
</style>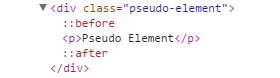
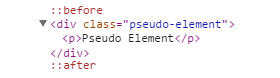
如上图所示,生成的两个伪元素分别处于 pseudo-element 元素的内部,并且分别位于 pseudo-element 元素的内容 p 标签的前面和后面,而不是如下图所示的位于 pseudo-element 元素外部的前面和后面:
2.9 层叠
层叠就是层叠样式表中的层叠,是一种样式在文档层次中逐层叠加的过程,目的是让浏览器面对某个标签特定属性值的多个来源确定最终使用哪个值。
层叠是 CSS 的核心机制,理解了它才能以最经济的方式写出最容易改动的 CSS,让文档外观在达到设计要求的同时,也给用户留下一些空间,让他们能根据需要更改文档的显示效果。
2.9.1 样式来源
作者在这一节中介绍了样式的几种来源:
-
浏览器默认样式表
-
用户样式表
-
作者链接样式表
-
作者嵌入样式
-
作者行内样式
作者在书中是这么描述的:
浏览器会按照上面的顺序依次检查每个来源的样式,并在有定义的情况下,更新对每个标签属性值的设定,整个检查更新过程结束后,再将每个标签以最终设定的样式显示出来。
2.9.4 计算特指度
作者在这一节主要介绍了特指度的计算方法,相比作者个计算方式,笔者个人还是比较喜欢自己之前的计算方式,虽然差不多,如下:
首先规定四个等级:A - B - C - D
- A 等级代表内联样式:例如
style=" ",权值为:1000; - B 等级代表 ID 选择器:例如
#main,权值为:100; - C 等级代表类、伪类和属性选择器:
.class和[title],权值为:10; - D 等级代表元素(标签)名或者伪元素选择器:例如
p和::after,权值为:1。
计算完每个值后再将每个值加起来,哪个值大哪个值的权重就高。
例如:
body #main .class a[title]::after {}我们先分析它由哪些选择器构成,上面这条规则有一个 id 选择器(#main),一个类选择器(.class),一个属性选择器([title])、一个伪元素选择器(::after)和两个标签名选择器(body 和 a),所以它的权重就等于:
100 × 1 + 10 × 2 + 1 × 3 = 123还有一点要注意的是,权重值 001(12) 与 0020 相比,任然是 0020 的权重更高,对于权重一样的情况,则后声明的样式更高。
2.10 小结
作者在本章介绍了 CSS 的一些规则,比如各种选择器的使用,层叠机制,还有权重的计算。